12 வது கணினி அறிவியல் : அலகு 13 : தரவுதள கருத்துருக்கள் மற்றும் MySql : பைத்தான் மற்றும் CSV கோப்புகள்
பைத்தான் மூலம் CSV கோப்பில் படிக்க மற்றும் எழுத
பைத்தான் மூலம் CSV கோப்பில் படிக்க மற்றும் எழுத
CSV கோப்புகளில் பல்வேறு செயல்பாடுகளை செய்ய பைத்தான் ஒரு
CSV என்ற செயற்கூற்றை வழங்கியுள்ளது. CSV கோப்பிலிருந்து அல்லது CSV கோப்பில் தரவினை
படித்தல், எழுதுதல் மற்றும் பல செயல்பாடுகளை செய்வதற்கு CSV-ன் நூலகமானது பொருட்கள்
மற்றும் பிற குறிமுறைகளை கொண்டுள்ளது.
உங்களுக்குத்
தெரியுமா?
CSV கோப்புகளானது நிகழ் நேர பயன்பாடுகளில் பரவலாக பயன்படுத்தப்படுகின்றன. ஏனெனில் அவை செயல்படுத்துவதற்கு எளிமையானவை.
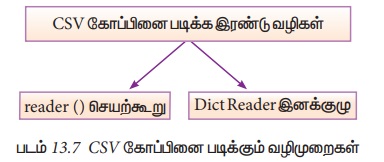
1. பைத்தான் பயன்படுத்தி CSV கோப்பினை படித்தல்
CSV கோப்பினை
படிக்க இரண்டு வழி முறைகள் உள்ளன.
1. CSV தொகுதி படித்தல் செயற்கூறை பயன்படுத்துதல்.
2. DictReader இனக்குழுவை
பயன்படுத்துதல்.
கோப்பினில் உள்ள தகவல்களை படிப்பதற்கோ அல்லது கோப்பினில் தகவல்களை
எழுதுவதற்கோ முதலில் கோப்பினை திறக்க வேண்டும். படித்தல் செயல் பாடானது முடிந்த பிறகு
கோப்பானது மூடப்பட வேண்டும். இதன் மூலம் கோப்பிற்கு நினைவகத்தில் ஒதுக்கப்பட்டுள்ள
இடம் விடுவிக்கப்படும்.
எனவே பைத்தானில் கோப்பு செயல்பாடானது பின்வரும் படிநிலைகளில்
செயல்படுத்தப்படுகிறது.

குறிப்பு
கோப்பினை
திறக்கும் open கட்டளையில் கோப்பின் பெயர் அல்லது கோப்பின் முழுமையான பாதையானது இரட்டை
மேற்கோள் குறிகளுக்குள் அல்லது ஒற்றை மேற்கோள் குறிகளுக்குள் கொடுக்கப்படல் வேண்டும்.
open() என்ற
உள்ளிணைந்த செயற்கூறு பைத்தானில் ஒரு கோப்பை திறக்கும் இந்த செயற்கூறு கோப்பு பொருள்
அல்லது திரும்பி கொடுக்கும், இதை பயன்படுத்தி கோப்பின் தரவுகளை படிக்கவோ அல்லது மாற்றவோ
முடியும். எடுத்துக்காட்டாக,
>>> f= open("sample.txt") # தற்போது கோப்புறையில்
கோப்பை திறக்க மற்றும் இதில் f என்பது கோப்பு பொருளை குறிக்கும்.
>>> f = open('c:\pyprg\ch13sample5.csv') # கோப்பின் முழுமையான
பாதையைக் குறிக்கும்.
கோப்பை திறப்பதற்கான முறைமையை பயனர் குறிப்பிடாலாம். பயனர் கோப்பினை
படிப்பதற்கு 'r', எழுதுவதற்கு 'W' அல்லது கோப்பின் இறுதியில் சேர்க்க 'a' என்ற கோப்பு
முறைமையை குறிப்பிடலாம். 'உரை அல்லது இருபரிமாண' (text or binary) என்ற ஏதேனும் ஒரு
முறைமையில் கோப்பினை திறக்க முறைமையை குறிப்பிடலாம்.
உரை முறைமை தான்மைவான கோப்பு பிடிக்கு முறைமையாகும். இதில்,
தரவை கோப்பிலிருந்து படிக்கும் போது தரவு சரங்களாக படிக்கப்படும். உரை அல்லது கோப்புகளான
படங்கள் அல்லது .exe கோப்புகளை படிக்கும் போது அவற்றை இருமநிலை முறைமையில் கையாளுதல்
செய்ய வேண்டும்.
பைத்தானில் கோப்பு முறைமைகள்
முறை / விளக்கம்
'r' படிப்பதற்க மட்டுமே ஒரு கோப்பினை திறக்கவும் (தானமைவு
நிலை)
‘w’ கோப்பில்
தரவுகளை எழுதுவதற்கு திறக்கவும். குறிப்பிடப்பட்ட கோப்பு இல்லையெனில் புதிய கோப்பினை
உருவாக்கும். கோப்பில் தரவுகள் இருப்பின் அவை அழிக்கப்படும்.
‘x’ தனித்துவமான
படைப்பிற்காக கோப்பினை திறக்கவும். கோப்பு முன்பே உருவாக்கப்பட்டிருந்தால் இந்த செயல்
முறையானது தோல்வியடையும்.
‘a’ கோப்பின்
தரவுகளை அழிக்காமல் அதன் இறுதியில் புதிய தரவுகளை சேர்ப்பதற்கு திறக்கவும். குறிப்பிடப்பட்ட
கோப்பு இல்லையெனில் புதிய கோப்பினை உருவாக்கும்.
't' உரை
முறைமையில் கோப்பு திறக்கவும் (தானமைவு நிலை)
‘b’ இருமநிலை
முறைமையில் கோப்பினை திறக்கவும்.
'+' புதுப்பித்தலிற்காக கோப்பினை திறக்கவும் (படித்தல்
மற்றும் எழுதுதல்)
F = open("sample.txt") # 'r' அல்லது 'rt' என்ற முறைமைகளுக்கு நிகர்
f =
open("sample.txt",'w') # உரை முறைமையில் கோப்பில் எழுத.
f=open("image1.bmp",'r+b') #இருமநிலை
முறைமையில் படித்தல் மற்றும் எழுதுதலுக்காக
நினைவகத்தின் பயன்பாட்டில் இல்லாத பொருள்களை (objects) சேகரிக்கவும்
மற்றும் அந்த நினைவக பகுதியை சுத்தம் செய்யவும். பைத்தானில் தேவையற்ற நினைவக பகுதியை
சேகரிக்கும் வசதி (Garbage collector) உள்ளது. ஆனால் இந்த வசதி கோப்புகளை மூடும் என்று
பயனர் நம்ப வேண்டாம்.
f =open("test.txt") # எந்த முறைமையும் குறிப்பிடப்படவில்லையெனில்
தானமைவாக rt என்ற முறைமை பயன்படும்
# n காப்பில் செயற்பாடுகள் செய்யவும்.
f.close()
மேலே குறிப்பிட்டுள்ள வழிமுறை பாதுகாப்பானது அல்ல, ஏதேனும் ஒரு
பிழை ஏற்படுமெனில் அந்த செயற்பாட்டிலிருந்து நிரலானது கோப்பை மூடாமல் வெளியேறும். இதை
சிறந்த முறையில் கையாள with கூற்றை பயன்படுத்தலாம். with தொகுதியிலிருந்து வெளியேறும்
போது அதனுள்ளே கொடுக்கப்பட்டுள்ள கோப்பு மூடப்படும். செயற்கூற்றை வெளிப்படையாக கொடுக்க
வேண்டியதில்லை. கோப்பு உள்ளமைவாகவே மூடப்படும்.
with open("test.txt",'r') as f:
# கோப்பு சார்ந்த செயல்பாடுகளை செய்ய
# என்பது கோப்பு பொருளாகும்.
கோப்பினை மூடும் போது அதனுடன் இணைக்கப்பட்டுள்ள வளங்கள் பைத்தானில்
close() செயற்கூறு மூலம் விடுவிக்கப்படும்.
f = open("sample.txt")
# கோப்பு சார்ந்த செயல்பாடுகள் செய்ய
f.close()
1. CSV-ன் Reader செயற்கூறு
CSV கோப்பின் உள்ளடக்கத்தை படிக்க CSv.reader() என்ற முறையானது
பயன்படுத்தப்படுகிறது. reader() செயற்கூறானது கோப்பின் ஒவ்வொரு வரியையும் படித்து அவற்றை
நெடுவரிசைகளின் பட்டியலாக (List) அமைக்கும். மாறியின் தரவிற்கு தேவையான நெடுவரிசையை
தேர்வு செய்யலாம்.. இச்செயற்கூறை பயன்படுத்தி பயனர் கோப்பின் தரவுகளில் உள்ள இரட்டை
மேற்கோள் குறி (“ ”), (i) மற்றும் (,) போன்ற பல்வேறு வடிவமைப்புகளை பயன்படுத்தி படிக்கலாம்.
Csv.reader()
செயற்கூறின்
தொடரியல்
Csv.reader(fileobject,delimiter,frntoarams)
இங்க ,
file object :- கோப்பின் பாதையையும் முறைமையும் திருப்பி அனுப்பும்.
delimiter :- இது விருப்பத்தேர்வு அளபுருவாகும். இது செந்தர
வரம்புக் குறிகளை கொண்டிருக்கும். (,’l ) போன்றவை மற்றவைகள் தவிர்க்கப்படும்.
fmtparams: கொடாநிலை மதிப்புகளை மேற்பதிப்பு செய்ய நீக்க பயன்படும்
விருப்பத்தேர்வு அளபுருவாகும்.
கோப்பு - கொடாநிலை பிரிப்பானான காற்புள்ளியை கொண்ட தரவு.

(a) கொடாநிலை பிரிப்பான் காற்புள்ளியுடன் கூடிய
CSV (,) கோப்புகள்
பின்வரும் நிரலானது கொடாநிலை பிரிப்பானான காற்புள்ளியுடன் கூடிய
"sample1.csv” என்ற கோப்பினை படித்து ஒவ்வொரு வரிசையாக அச்சிடும் நிரல்.
#importing csv
import csv
#opening the csv file which is in different location with read
mode
with open('c:\pyprg\sample1.csv', 'r') as F:
#other way to open the file is f= ('c:\pyprg\sample1.csv', 'r')
reader = csv.reader(F)
for row in reader :
# printing each line of the Data row by row
print(row)
F.close()
வெளியீடு
('SNO', 'NAME', 'CITY']
[12101', 'RAM', 'CHENNAI']
['12102', 'LAVANYA', 'TIRUCHY']
['12103', 'LAKSHMAN', 'MADURAI')
(b) தொடக்கத்தில்
இடைவெளிகளுடன் கூடிய தரவினைக் கொண்ட CSV கோப்பு
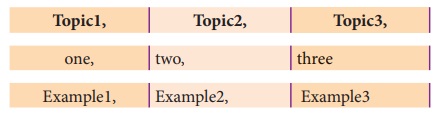
பின்வரும் sample2.cSV என்ற கோப்பினை கருத்தில் கொள்ளவும்.
NOTEPAD பயன்பாட்டில்
மூலம் திறக்கும் போது பின்வருமாறு தரவினை கொண்டிருக்கும்.
பின்வரும் நிரலானது பைத்தானில் உள்ள CSv.reader() என்ற செயற்கூறு
மூலம் கோப்பினை படிக்கிறது.
import
csv
csv.register_dialect('myDialect',delimiter=
',', skipinitialspace=True)
F=open('c:\pyprg\sample2.csv','r')
reader
= csv.reader(F, dialect='myDialect')
for
row in reader:
print(row)
F.close()
வெளியீடு
('Topic1',
'Topic2', 'Topic3']
('one',
'two', 'three']
('Example1',
'Example2', 'Example3']
"sample2.csv” கோப்பில் காண்பதை போல் பிரிப்பானான காற்புள்ளிக்கு
அடுத்து வரும் வெற்று இடைவெளிகளால் வெளியீடும் வெற்று இடைவெளிகளுடன் தோன்றும்.
வெற்று இடைவெளிகளானது CSV செயற்கூறினுள் உள்ள
csv.register_dialect() என்ற இனக்குழுவின் மூலம் நீக்கலாம். dialect ஆனது CSV கோப்பினை
படிப்பதற்கான வழிமுறைகளை விவரிக்கிறது. dialects-ல் "skipinitialspace” என்ற அளபுருவானது
பிரிப்பானிற்கு அடுத்து வரும் வெற்று இடைவெளிகளை நீக்க உதவுகிறது.
குறிப்பு
தானமைவாக
"skipinitialspace” என்பதன் மதிப்பு false ஆகும்.
கீழேயுள்ள நிரலானது "sample2.csv”
என்ற கோப்பில், பிரிப்பானற்க்கு பிறகுயுள்ள வெற்றிடைவெளிகளை படிக்கின்றது.
import csv
Csv.register_dialect('myDialect', delimiter=',',
skipinitialspace=True)
F=open('c:\pyprg\sample2.csv','r')
reader = csv.reader(F, dialect='myDialect')
for row in reader:
print(row)
F.close()
வெளியீடு
('Topic1', 'Topic2', 'Topic3']
('one', 'two', 'three']
('Example1', 'Example2', 'Example3']
மேற்கண்ட நிரலில் புதிய dialect ஆனது (delimiter=', ') காற்புள்ளி
பிரிப்பாணை கொண்டுள்ளது. மேலும் d skipinitialspace என்பதன் மதிப்பு True என அமைக்கப்பட்டுள்ளது.
இது பிரிப்பானிற்கு அடுத்து வரும் வெற்று இடைவெளிகளை தவிர்த்திடுமாறு நிரல் பெயர்ப்பிக்கு
உணர்த்தும்.
குறிப்பு
csv
-ல் படிப்பதற்கு மற்றும் எழுதுவதற்கு உள்ள அளபுருக்களை வரையறுக்க dialect என்ற இனக்குழு
CSV செயற்கூறில் பயன்படுகிறது. இது தரவை வடிவூட்டம் செய்வதற்கான பல்வேறு உருவாக்க,
சேமிக்க மற்றும் மறுபயனாக்க பயன்படும் அளபுருக்களை கொண்டுள்ளது,
(c) மேற்கோள் குறிகளுடன் CSV கோப்பு
CSV செயற்கூறில் உள்ள Csv.register_dialect() என்ற புதிய இனக்குழுவை
பதிவதன் மூலம் இரட்டை மேற்கோள் குறிகளுடன் கூடிய CSV கோப்பினை படிக்கலாம்.
quotes.CSV என்ற கோப்பானது பின்வரும் தரவுகளை கொண்டிருக்கும்.
SNO,Quotes
1, "The secret to getting ahead is getting started."
2, "Excellence is a continuous process and not an
accident."
3, "Work hard dream big never give up and believe
yourself." 4, "Failure is the opportunity to begin again more
intelligently."
5, "The successful warrior is the average man, with
laser-like focus."
பின்வரும் நிரலானது காற்புள்ளியை பிரிப்பானாக கொண்டிருக்கும்
"quotes.csv” என்ற கோப்பினை படிக்கும். ஆனால் இரட்டை மேற்கோள் குறிகளானது மற்றுமொரு
மேற்கோள் குறிகளுக்குள் கொடுக்கப்பட்டிருக்கும்.
import csv
Csv.register_dialect('myDialect', delimiter = ',',quoting=csV.QUOTE_ALL,
skipinitialspace=True)
f=open('c:\pyprg\quotes.csv','r')
reader = csv.reader(f, dialect='myDialect')
for row in reader:
print(row)
வெளியீடு
('SNO', 'Quotes']
['1', 'The secret to getting ahead is getting started.']
['2', 'Excellence is a continuous process and not an accident.']
['3', 'Work hard dream big never give up and believe yourself.']
['4', 'Failure is the opportunity to begin again more
intelligently.']
['5', 'The successful warrior is the average man, with
laser-like focus. ']
மேற்கண்ட நிரலில் myDialect என்ற பெயருடன் கூடிய புதிய
Dialect பதிவு செய்யப்பட்டுள்ளது. CSV. QUOTE_ALL என்ற கோப்பினை பயன்படுத்தும் போது
அனைத்து குறியுருக்களும் மேற்கோள் குறிக்க அடுத்து வெளிப்படுத்தலாம்.
(d) தனிப்பயனாக்கப்பட்ட பிரிப்பானைக் கொண்ட CSV கோப்பு
csv.register_dialect() என்பதன் உதவியுடன் புதிய dialect-ஐ பதிவு
செய்து தனிப்பயனாக்கப்பட்ட பிரிப்பானைக் கொண்ட CSV கோப்புகளை படிக்க முடியும்.
பின்வரும் "sample4.csv”
என்ற கோப்பானது பைப் (Pipe symbol) குறியீட்டைக் கொண்டு புலங்கள் பிரிக்கப்பட்டுள்ளது.

பின்வரும் நிரலானது பயனரால் வரையறுக்கப்பட்டுள்ள பிரிப்பானைக்
கொண்டுள்ள | (Pipe symbol) “sample4.csv” என்ற கோப்பினை படிக்கும்.

மேற்கண்ட நிரலில் My Dialect என்ற பெயரில் புதிய dialect ஆனது பதிவு செய்யப்பட்டுள்ளது. இதில் (Pipe symbol) ஆனது புலத்தை பிரிக்கும் பிரிப்பானாக அமைக்கப்பட்டுள்ளது.
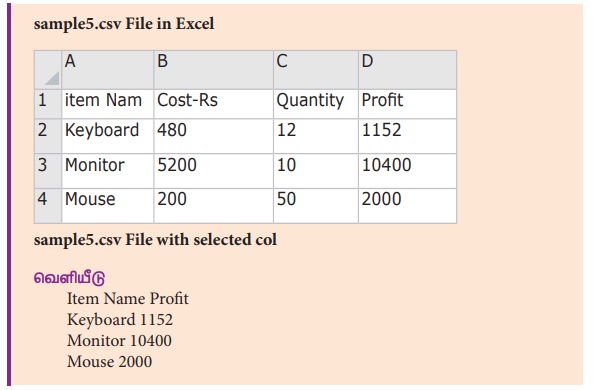
2. ஒரு கோப்பினில் குறிப்பிட்ட புலத்தை மட்டும் படித்தல்
"sample5.csv” என்ற கோப்பினில் உள்ள Item Name மற்றம்
profit போன்ற குறிப்பிட்ட புலங்களை மட்டும் படிக்க கீழ்க்காணும் வழிமுறைகளை செய்தல்
வேண்டும்.
import csv
#opening the csv file which is in different
location with read mode
f=open("c:\pyprg\ch13sample5.csv",'r')
#reading the File with the help of
csv.reader()
readFile=csv.reader(f)
#printing the selected column
for col in readFile :
print (coll[0],col[3])
f.close()
3 CSV கோப்பினை படித்தல் மற்றும் பட்டியலாக சேமித்தல்
இப்பகுதியில் CSV கோப்பினை படித்தல் மற்றும் கோப்பின் உள்ளடக்கத்தை
பட்டியலாக சேமித்தல் முறையை பற்றி படிக்க இருக்கிறோம். பட்டியலாக சேமிப்பதற்கான தொடரியல்

எடுத்துக்காட்டு பின்வரும் நிரலானது "sample.csv"
கோப்பின் அனைத்து வரிசையில் உள்ள மதிப்புகளையும் பட்டியலாக சேமிக்கும்.
import csv
# other way of declaring the filename
inFile='c:\pyprg\sample.csv'
F=open(inFile,'r')
reader = csv.reader(F)
# declaring
array array Value = []
# displaying the content of the list
for row in reader:
arrayValue.append(row)
print(row)
F.close()

குறிப்பு
வரிசைப்படுத்தப்பட்ட
உறுப்புகளின் வரிசையை மாற்றக்கூடிய தரவு கட்டமைப்பு பட்டியல் (List) ஆகும்.
உங்களுக்குத் தெரியுமா?
நிலையுருக்களின் பட்டியலானது சதுர வடிவ அடைப்புக் குறிகளுக்குள் எழுதப்படல் வேண்டும். List-ஆக சரங்களை ஒத்ததாகும்.
4. வரிசையாக்கம் செய்வதற்காக CSV கோப்பினை படித்தது புலத்தின் மதிப்புகளை List-ல் சேமித்தல்
இந்த நிரலானது “sample6.csv” என்ற கோப்பினில் இருந்து பயனரால்
தரப்படும் எண்ணிற்குரிய நெடுவரிசையின் பொருளடக்கத்தை படித்து அதை List -ல் சேமிக்கும்.
வரிசையின் தலைப்புக்களும் சேர்த்து வரிசைப்படுத்தப்படுவதை தவிர்க்க
வரிசைப்படுத்தும் போது முதல் வரிசையானது தவிர்க்கப்படல் வேண்டும். “next()” என்ற கட்டளை
மூலம் இதை செயல்படுத்த முடியும். List -ஆனது வரிசையப்படுத்தப்பட்டு வெளியிடப்பட்டுள்ளது.
தலைப்பு நெடுவரிசையை தவிர்த்து பயனர் தேர்ந்தெடுத்த நெடுவரிசையை
வரிசையாக்கம் செய்ய
# sort a selected column given by user leaving the header column
in descending order
import csv
# other way of declaring the filename
inFile= 'c:\pyprg\sample6.csv'
# opening the csv file which is in the same location where the
content of the python file is there.
python file
F=open(inFiler')
# reading the File with the help of csv.reader()
reader = csv.reader(F)
# skipping the first row(heading)
next(reader)
# declaring a list
arrayValue = [ ]
a = int(input (“Enter the column number 1 to 3:-"))
# sorting a particular column-cost
for row in reader:
arrayValue.append(row[a])
arrayValue.sort(reverse=True)
for row in arrayValue: -
print (row)
F.close()
வெளியீடு
Enter the column number between 0 to 3:- 2
50
12
10
குறிப்பு
ஒரு
சிஎஸ்வி கோப்பில் ஒரு குறிப்பிட்ட நெடுவரிசையைப் படித்து அதன் முடிவை ஏறுவரிசையில்
காண்பி
உங்களுக்குத்
தெரியுமா?
list_name.sort()
கட்டளையானது பட்டியலில் உள்ள உறுப்புகளை ஏறு வரிசையில் (ascending) வரிசைப்படுத்தும்.
list_name.sort(reverse) கட்டளையானது பட்டியலில் உள்ள உறுப்புகளை இறங்கு (descending) வரிசையில் ஒழுங்குபடுத்தும்.
5. CSV கோப்பினில் உள்ள ஒரு குறிப்பிட்ட புலத்தை வரிசையாக்கம் செய்தல்.
இந்நிலையானது “sample8.csv” என்ற கோப்பின் முழு பொருளடக்கத்தையும்
படித்து பட்டியலுக்கு மாற்றம் செய்யும். அதன் பிறகு quantity என்ற புலத்தில் உள்ள வரிசைகளின்
பட்டியலானது வரிசையாக்கம் செய்யப்பட்டு ஏறுவரிசையில் வெளிப்படுத்தப்படும். ஒன்றுக்கு
மேற்பட்ட புலங்களை வரிசைப்படுத்த itemgetter என்பதில் ஒன்றுக்கு மேற்பட்ட சுட்டு எண்களை
குறிப்பிடுவதன் மூலம் நிறைவேற்றலாம். operator.itemgetter(col_no) என்ற கோப்பின் பொருளடக்கமானது

பின்வரும் நிரலானது operator.itemgetter(col_no)
என்பதை பயன்படுத்தி மேற்குறிப்பிட்ட நிரலை நிறைவேற்றுகிறது.
#Program to sort the entire row by using a specified column.
# declaring multiple header files
import csv ,operator
#One more way to read the file
data = csv.reader(open('c:\PYPRG\sample8.csv'))
next(data) #(to omit the header)
#using operator module for sorting multiple columns
sortedlist = sorted (data, key=operator.itemgetter(1))
# 1 specifies we want to sort
# according to second column
for row in sortedlist:
print(row)
வெளியீடு
[Mouse', '20']
['Keyboard, 48']
[Monitor', '52']
குறிப்பு
sorted() முறையானது / செயல்கூறானது
ஒரு குறிப்பிட்ட வரிசையில் கொடுக்கப்பட்டபடி உறுப்புகளை ஏறுவரிசையிலோ அல்லது இறங்கு
வரிசையிலோவரிசைப்படுத்தும். sort() முறையானது sorted() முறையை ஒத்திருக்கும். ஒரு வேறுபாடானது
sort() முறை எந்த மதிப்பையும் திரும்ப தராது மேலும்மூல பட்டியலில் மாற்றத்தை ஏற்படுத்தும்.
செய்முறைப்பயிற்சி:
“sample8.csv” என்ற கோப்பினில் “cost” எனும்
மேலும் ஒரு புலத்தை சேர்த்து அதன் பொருள் இறங்கு வரிசையில் வரிசையாக்கம் செய்ய பின்வரும்
தொடரியலானது பயன்படுகிறது.
தொடரியல்
sortedlist = sorted(data, key=operator.itemgetter(Col_number),reverse=True)
6. CSV கோப்பினை Dictionary படிக்க
CSV செயற்கூறிலுள்ள
DictReader இனக்குழுவை பயன்படுத்தி CSV கோப்பை படித்தல். இதன் செயல்பாடு reader() இனக்குழு செயல்பாட்டை ஒத்திருக்கும்.
ஆனால் இது ஒரு பொருளை உருவாக்கி அதை Dictionaryயில் இணைக்கும்.
DictReader
CSV
கோப்பில் உள்ள முதல் வரியை காற்புள்ளியை இந்த வரியின் Dictionary திறவுகோள் (Dictionary
Key) பயன்படுத்தி படிக்கும். அடுத்தடுத்துள்ள வரிசையில் உள்ள நெடுவரிசையானது
Dictionaryயின் மதிப்புகளாக செயல்பட்டு அவற்றை உரிய திறவுகோள் மூலம் அணுக முடியும்
(புலத்தின் பெயர்)
CSV கோப்பின்
முதல் வரிசையானது புலப்பெயரை கொண்டிருக்கவில்லையெனில் புலப்பெயர் அளபுருவை
DictReader's ஆக்கிக்கு அனுப்பி Dictionary திறவுகோள்களை நாமாக ஒதுக்க முடியும்.
csv.reader() மற்றும்
DictReader() க்கு இடையேயான முக்கிய வேறுபாட்டை
எளிமையாக கூறுவதெனில் CSv.reader மற்றும் CSV.writer ஆனது பட்டியல் (list/tuple) பதிவுடன்
வேலை செய்யும். CSV. DictReader மற்றும் CSV.DictWriter ஆனது அகராதியில் வேலை செய்யும்.
import csv
filename = 'c:\pyprg\sample8.csv'
input_file =csv.DictReader(open(filename'r'))
for row in input_file:
print(dict(row))
#dict() to print data
வெளியீடு
{ItemName : Keyboard , 'Quantity': ‘48'}
{'Item Name: 'Monitor, Quantity': '52"}
{'ItemName : 'Mouse , Quantity': '20'}
Csv.DictReader மற்றும் CSV.DictWriter இரண்டும் கூடுதல் அளபுருவாக
புலப்பெயரினை பெற்று Dictionary திறவுகோளாக பயன்படுத்தும்.
(எடுத்துக்காட்டாக) “sample8.csv” என்ற கோப்பானது Dictionary -யை படித்தல்.
செயல்முறை:
மேலே கொடுக்கப்பட்டுள்ள நிரலில் dict() செயல்கூறில் நீக்கவும் மற்றும்
print(row) பயன்படுத்தவும். கீழே கொடுக்கப்பட்டுள்ள வெளியீடை தரும்.
OrderedDict([('ItemName > Keyboard'), ('Quantity', 48')])
OrderedDict([('TtemName', Monitor'), ('Quantity', `52')])
OrderedDict([('ItemName', 'Mouse ), ('Quantity', 20')])
7. Dictionary பயனர் வரையறுத்த பிரிப்பானை பயன்படுத்தி CSV கோப்பினை படித்தல்
புதிய Dialects ஐ பதிவு செய்து DictReader() செயற்கூறில் நாம்
அதை பயன்படுத்த முடியும். "sample8.csv” கோப்பானது பின்வரும் வடிவத்தில் இருந்தால்

import csv
csv.register_dialect('myDialect,delimiter =
'|,skipinitialspace=True)
filename = 'c:\pyprg\ch13\sample8.csv'
with open(filename, r') as csvfile:
reader = csv.DictReader(csvfile, dialect='myDialect')
for row in reader:
print(dict(row))
csvfile.close()
வெளியீடு
{ItemName ,Quantity': 'Keyboard ,48'}
{ItemName ,Quantity': 'Monitor,52'}
{ItemName ,Quantity': 'Mouse ,20'}
குறிப்பு
DictReader()
தானமைவாக ordereddict என்பதை வெளியீடும். Dictionaryயின் ஒரு துணைகுழுவாக
Ordereddict செயல்படும் இது உள்ளடக்கத்தைக்கும் அவற்றை சேமிக்கும் வரிசையில் சேர்க்கும்.
Ordereddict நீக்க Dict() யை பயன்படுத்தவும்.